

Cientistas de Dados Ganham R$22 mil?
A pergunta que ficou famosa na comunidade dos cientistas de dados finalmente poderá ser respondida. Afinal, um cientista de dados no Brasil ganha R$ 22 mil por mês?
Para responder esta pergunta, seguiremos os seguintes passos:
1. Importação do Dataset e das Bibliotecas
O Dataset utilizado foi retirado do Data Hackers Survey 2019 uma pesquisa de mercado realizada por uma das maiores comunidades de Data Science do Brasil, conhecida como Data Hackers.
A pesquisa foi conduzida de forma online durante o mês de novembro de 2019 e teve como objetivo entender um pouco melhor a situação do mercado de data science no Brasil. Mais de 1700 pessoas responderam a pesquisa, compartilhando desde faixa salarial até quais ferramentas mais usam no trabalho.
Os resultados obtidos por este survey foram disponibilizados no Kaggle, após sofrer certas manipulações visando sua completa anonimização. As perguntas feitas durante a pesquisa podem ser observadas no dicionário do dataset.
As bibliotecas importadas para a manipulação e visualização destes dados são as seguintes:
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
pd.options.display.max_columns = None
A biblioteca pandas foi utilizada para a manipulação dos dados através de dataframes, enquanto seaborn e matplotlib auxiliam na visualização dos dados em gráficos.
2. Análise e Manipulação do Dataset
Após realizada uma análise primária sobre o dataset, algumas manipulações no mesmo foram considerdas necessárias. Algumas dados do dataset foram removidos, uma vez que que não se adequam a análise dos salários de cientistas de dados. São eles:
- Dados que não possuem uma especificação de salário (coluna
('P16', 'salary_range')). - Dados em que a pessoa não está empregada via CLT (coluna
('P10', 'job_situation')). - Dados em que a pessoa não se considera atuante em data science (coluna
('P19', 'is_data_science_professional')). - Dados onde a pessoa atualmente não reside no Brasil, visto que queremos saber especificamente sobre o salário no Brasil (coluna
('P3', 'living_in_brasil')).
O dataset inicial disponível no Kaggle possui 1765 linhas e 170 colunas.
Para se remover os dados que não possuem uma especificação de salário (coluna ('P16', 'salary_range')), foi utilizado o seguinte código:
data = data[data["('P16', 'salary_range')"].notna()]
Para se remover os dados em que a pessoa não está empregada via CLT (coluna ('P10', 'job_situation')), foi utilizado o seguinte código:
data = data[data["('P10', 'job_situation')"] == 'Empregado (CTL)']
Para se remover os dados em que a pessoa não se considera atuante em data science (coluna ('P19', 'is_data_science_professional')), foi utilizado o seguinte código:
data = data[data["('P19', 'is_data_science_professional')"] == 1]
E por fim, para se remover os dados onde a pessoa atualmente não reside no Brasil (coluna ('P3', 'living_in_brasil')) foi utilizado o seguinte código:
data = data[data["('P3', 'living_in_brasil')"] == 1]
Com isso, o dataset acabou sendo reduzido para 552 linhas e permaneceu com 170 colunas. Por fim, criamos uma nova coluna no dataframe com o nome salary, apenas para facilitar a manipulação.
3. Visualização de Dados
Para a visualização dos dados, resolvemos tentar transmitir toda a informação necessária em apenas um gráfico. Com isso, a complexidade do gráfico em si aumentou, pois tentamos criar uma manipulação onde se é possível analisar o eixo y a partir do número de entrevistados ou de sua respectiva frequência (%).
Primeiro, definimos uma ordem nos salários para que o gráfico seguisse uma linha crescente de salários no eixo x, através da variável salary_order. Em seguida plotamos um countplot da biblioteca seaborn, passando os dados do dataframe como parámetro e ordenados pela variável salary_order. Nomeamos então o título e o eixo x do gráfico, como se é feito corriqueiramente.
salary_order = ['Menos de R$ 1.000/mês',
'de R$ 1.001 à 2.000/mês',
'de R$ 2.001 à 3.000/mês',
'de R$ 3.001 à 4.000/mês',
'de R$ 4.001 à 6.000/mês',
'de R$ 6.001 à 8.000/mês',
'de R$ 8.001 à 12.000/mês',
'de R$ 12.001 à 16.000/mês',
'de R$ 16.001 à 20.000/mês',
'de R$ 20.001 à 25.000/mês',
'Acima de R$ 25.001/mês']
plt.figure(figsize=(15,10))
ax = sns.countplot(x="salary", data=data, order=salary_order)
plt.title('Salário dos Cientistas de Dados', size=14)
plt.xlabel('Variação dos Salários', size=12)
Para a manipulação de dois eixos y, foi utilizada a função twinx() que tem como objetivo duplicar o eixo y do gráfico enquanto mantém o eixo x intacto. Em seguida, moveu-se os novos eixos y para esquerda e direita, com as funções yaxis.tick_left() e yaxis.tick_right() e seus respectivos rótulos com a função yaxis.set_label_position().
ax2 = ax.twinx()
ax.yaxis.tick_right()
ax2.yaxis.tick_left()
ax.yaxis.set_label_position('right')
ax2.yaxis.set_label_position('left')
ax.set_ylabel("Número de Entrevistados", size=12, labelpad=12)
ax2.set_ylabel('Frequência [%]', size=12)
Em seguida, certas manipulações foram feitas com relação ao eixo x, tentando facilitar a leitura e visualização do gráfico, com a rotação dos rótulos.
ax.tick_params(axis='x', labelsize=12)
ax.set_xticklabels(ax.get_xticklabels(), rotation=45
horizontalalignment='right')
Foi feita então uma manipulação para que sobre cada barra do countplot, existisse a frequência exata da dimensão daquela barra, permitindo uma melhor interpretação do gráfico.
for p in ax.patches:
x = p.get_bbox().get_points()[:,0]
y = p.get_bbox().get_points()[1,1]
ax.annotate('{:.1f}%'.format(100. * y / len(data)),
xy=(x.mean(), y), ha='center', va='bottom')
Por fim, são definidos os bins de ambos os eixos y, enfatizando na facilidade na visualização de ambos, alinhando o máximo possível os seus valores.
ax.yaxis.set_major_locator(ticker.LinearLocator(11))
ax2.yaxis.set_major_locator(ticker.MultipleLocator(10))
ax2.set_ylim(0, 100)
ax.set_ylim(0, 200)
ax2.grid(None)
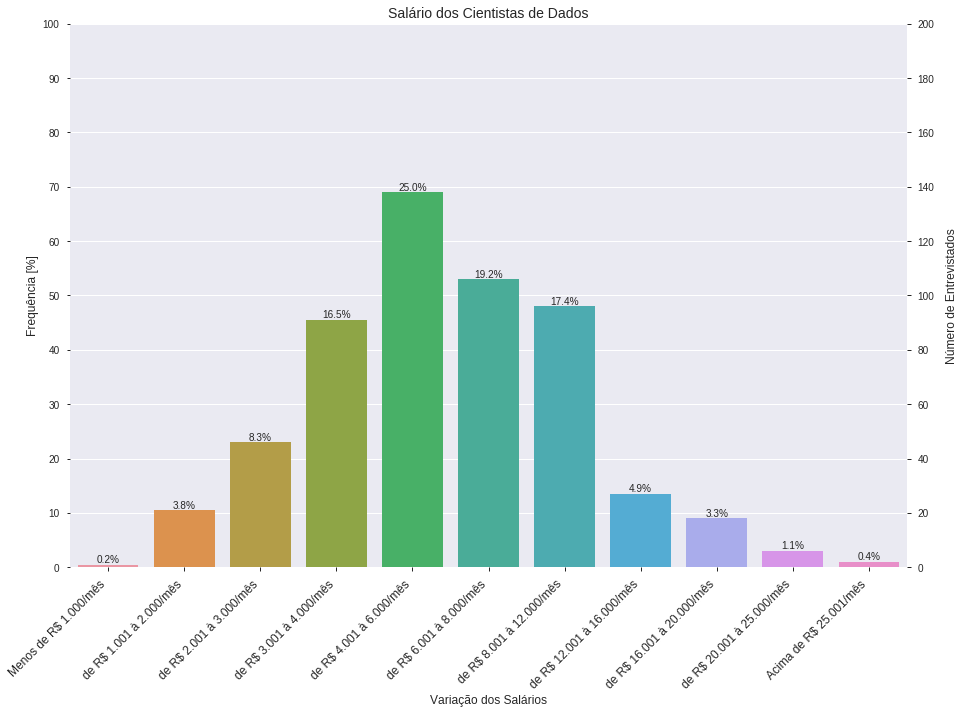
Este código gera então o seguinte gráfico:
Caso considere necessário, o código completo está disponível em um notebook no Kaggle.
Com este gráfico, podemos então tirar algumas conclusões a respeito do salário do cientista de dados no Brasil:
-
Fica claro que a realidade salarial dos cientistas de dados no Brasil não está nem próxima de 22 mil reais, girando dentro da casa dos 3 à 12 mil reais por mês (~78% dos entrevistados ganham dentro desta faixa salarial).
-
Apenas 1.1% dos entrevistados recebem algo próximo à 22 mil reais, enquanto apenas 0.4% recebem mais do que 25 mil reais, enfatizando o quanto o salário médio de um cientista de dados não está nem perto do divulgado.